If you find any typos, errors, or places where the text may be improved, please let us know
by providing feedback either in the feedback survey (given during class) or
by using GitHub.
On GitHub open an
issue
or submit a pull request
by clicking the " Edit this page" link at the side of this page.
3Pre-course tasks
In order to participate in this course, you must complete this section for the pre-course tasks and finish with completing the survey at the end. These tasks are designed to make it easier for everyone to start the course with everything set up. For some of the tasks, you might not understand why you need to do them, but you will likely understand why once the course begins.
Depending on your skills and knowledge, these tasks could take between 3-7 hrs to finish, so we suggest planning a full day to complete them. Depending on your institution and how they handle installing software on work computers, you also might have to contact IT very early to make sure everything is properly installed and set up.
3.1 List of tasks
Here’s the list of tasks you need to do. Specific details about them are found as you work through the tasks.
Read the learning objectives in Section 3.2 for the pre-course tasks (below).
Follow the installation instructions in Section 3.4. Install a version of R, RStudio, and Git that is as updated as possible. For some people, depending on their institution, this task can take the longest amount of time because you have to contact your IT to install these packages.
Read about Git from the introduction course and configure Git on your computer in Section 3.6. If you haven’t used Git before, this task could take a while because of the reading. Run the checks in this subsection to see if everything works. You’ll later need to paste this output into the survey.
Create an R Project in Section 3.7, including the folder and files.
Write R code to download the data in Section 3.9 and save it to your computer. This task will probably take up the most time, maybe 30-90 minutes. Run a check in this subsection to see that everything is as expected. You’ll later need to paste this output into the survey.
Read about the basic course details in Section 3.10.
Complete the pre-course survey. This survey is pretty quick, maybe ~10 minutes.
Check each section for exact details on completing these tasks.
3.2 Learning objectives
In general, these pre-course tasks are meant to help prepare you for the course and make sure everything is setup properly so the first session runs smoothly. However, some of these tasks are meant for learning as well as for general setup, so we have defined the following learning objectives for this page:
Learn about making reproducible documents with Quarto.
Learn about filesystems, relative and absolute paths, and how to make use of the fs R package to navigate files in your project.
Learn where to store your raw data so that you can use scripts as a record of what was done to process the data before analyzing it, and why that’s important.
3.3 Reading the course website
We will explain this a bit during the course, but read this to start learning how the website is structured and how to read certain things. Specifically, there are a few “syntax” type formatting of the text in this website to be aware of:
Folder names always end with a /, for example data/ means the data folder.
R variables are always shown as is. For instance, for the code x <- 10, x is a variable because it was assigned with 10.
Functions always end with (), for instance mean() or read_csv().
Sometimes functions have their package name appended with :: to indicate to run the code from the specific package, since we likely haven’t loaded the package with library(). For instance, to install packages from GitHub using the pak package we use pak::pkg_install("user/packagename"). You’ll learn about this more later.
Reading tasks always start with a statement “Reading task” and are enclosed in a “callout block”. Read within this block. We will usually go over the section again to reinforce the concepts and address any questions.
3.4 Installing the latest programs
The first thing to do is to install these programs. You may already have some of them installed and if you do, please make sure that they are at least the minimum versions listed below. If not, you will need to update them.
R: Any version above 4.1.2. If you have used R before, you can confirm the version by running R.version.string in the Console.
RStudio: Any version above v2021.09.0+351. If you have installed it before, check the current version by going to the menu Help -> About RStudio.
Git: Select the “Click here for download” link. Git is used throughout many sessions in the courses. When installing, it will ask for a selecting a “Text Editor” and while we won’t be using this in the course, Git needs to know this information so choose Notepad.
Rtools: Version that says “R-release”. Rtools is needed in order to build some R packages. For some computers, installing Rtools can take some time.
R: Any version above 4.1.2. If you have used R before, you can confirm the version by running R.version.string in the Console. If you use Homebrew, installing R is as easy as opening a Terminal and running:
brew install --cask r
RStudio: Any version above v2021.09.0+351. If you have installed it before, check the current version by going to the menu Help -> About RStudio. With Homebrew:
brew install --cask rstudio
Git: Git is used throughout many sessions in the courses. With Homebrew:
brew install git
R: Any version above 4.1.2. If you have used R before, you can confirm the version by running R.version.string in the Console.
sudo apt -y install r-base
RStudio: Any version above v2021.09.0+351. If you have installed it before, check the current version by going to the menu Help -> About RStudio.
Git: Git is used throughout many sessions in the courses.
sudo apt install git
All these programs are required for the course, even Git. Git, which is a software program to formally manage versions of files, is used because of it’s popularity and the amount of documentation available for it. At the end of the course, you will be using Git and GitHub to manage your group assignment. Check out the online book Happy Git with R, especially the “Why Git” section, for an understanding on why we are teaching Git. Windows users tend to have more trouble with installing Git than macOS or Linux users. See the section on Installing Git for Windows for help.
Note
Some pictures may show a Git pane in RStudio, but you may not see it. If you haven’t created or opened an RStudio R Project (which is taught in the introductory course), the Git pane does not show up. It only shows up in R Projects that use Git to track file changes.
Note
A note to those who have or use work laptops with restrictive administrative privileges: You may encounter problems installing software due to administrative reasons (e.g. you don’t have permission to install things). Even if you have issues installing or updating the latest version of R or RStudio, you will likely be able to continue with the course as long as you have the minimum version listed above for R and for RStudio. If you have versions of R and RStudio that are older than that, you may need to ask your IT department to update your software if you can’t do this yourself. Unfortunately, Git is not a commonly used software for some organizations, so you may not have it installed and you will need to ask IT to install it. We require it for the course, so please make sure to give IT enough time to be able to install it for you prior to the course.
Once R, RStudio, and Git have been installed, open RStudio. If you encounter any troubles during these pre-course tasks, try as best as you can to complete the task and then let us know about the issues in the pre-course survey of the course. If you continue having problems, indicate on the survey that you need help and we can try to book a quick video call to fix the problem. Otherwise, you can come to the course 15-20 minutes earlier to get help.
If you’re unable to complete the setup procedure due to unfixable technical issues, you can use Posit Cloud (to use RStudio on the cloud) as a final solution in order to participate in the course. For help setting up Posit Cloud for this course, refer to the Posit Cloud setup guide.
3.5 Installing the R packages
We will be using specific R packages for the course, so you will need to install them. A detailed walkthrough for installing the necessary packages is available on the pre-course tasks for installing packages section of the introduction course, however, you only need to install the r3 helper package in order to install all the necessary packages by running these commands in the R Console:
You might encounter an error when running this code. That’s ok, you can fix it if you restart R by going to Sessions -> Restart R and re-run the code in items 2 and 3, it should work. If it still doesn’t, try to running:
remotes::install_github("rostools/r3")
If that also doesn’t work, try to complete the other tasks, complete the survey, and let us know you have a problem in the survey.
The normal way of doing this would be to load the package with library(r3) and then running the command (install_packages_intermediate()). But by using the ::, we tell R to directly use a function from a package, without needing to load the package and all of its other functions too. We use this trick because we only want to use the install_packages_intermediate() command from the r3 package and not have to load all the other functions as well. In this course we will be using :: often.
3.6 Setting up Git
Since Git has already been covered in the Introduction course, we won’t cover learning it during this course. However, since version control is a fundamental component of any modern data analysis workflow and should be used, we will be using it throughout the course. If you have used or currently use Git, you can skip this section. If you haven’t used it, please do these tasks:
Follow the pre-course tasks for Git (not the GitHub tasks) from the introduction course. Specifically, type in the RStudio Console:
Console
# A pop-up to type in your name (first and last), # as well as your emailr3::setup_git_config()
Please read through the Version Control lesson of the introduction course. You don’t need to do any of the exercises or activities, but you are welcome to do them if it will help you learn or understand it better. For most of the course, we will be using Git as shown in the Using Git in RStudio section. Later on during the course, we might connect our projects to GitHub, which is described in the Synchronizing with GitHub section.
Regardless of whether you’ve done the steps above or not, everyone needs to run:
Console
r3::check_setup()
The output you’ll get for success will look something like this:
Checking R version:
✔ Your R is at the latest version of 4.2.0!
Checking RStudio version:
✔ Your RStudio is at the latest version of 2022.2.2.485!
Checking Git config settings:
✔ Your Git configuration is all setup!
Git now knows that:
- Your name is 'Luke W. Johnston'
- Your email is 'lwjohnst@gmail.com'
Eventually you will need to copy and paste the output into one of the survey questions. Note that while GitHub is a natural connection to using Git, given the limited time available, we will not be going over how to use GitHub. If you want to learn about using GitHub, check out this session on it in the introduction course.
3.7 Create an R Project
One of the basic steps to reproducibility and modern workflows in data analysis is to keep everything contained in a single location. In RStudio, this is done with R Projects. Please read all of Section 7.1 from the introduction course to learn about R Projects and how they help keeping things self-contained. You don’t need to do any of the exercises or activities.
Before creating and setting up the project folder, there are two things we strongly strongly encourage:
Don’t create the project on your Dropbox, OneDrive, or other backup/synching service. The reason being that they don’t integrate well with Git because of how they synchronize things. Plus, we will be re-generating files often, which causes these services to constantly be working to synchronize these files.
Don’t create the project on any shared drive (like H: or E: or U: drives on Windows). Because these folders are remote locations on an external server, they can really slow things down when working with Git, R, and RStudio. Create the project on your actual computer, like the C: drive in Windows or /Users/ on Mac.
These two things are the biggest source of errors, troubleshooting, and issues with participants when they do the course.
There are several ways to organise a project folder. We’ll be using the structure from the package prodigenr. The project setup can be done by either:
Using RStudio’s New Project menu item: “File -> New Project -> New Directory”, scroll down to “Scientific Analysis Project using prodigenr” and name the project “LearnR3” in the Directory Name, saving it to the “Desktop” with Browse.
Or, running the command prodigenr::setup_project("~/Desktop/LearnR3") in the R Console.
When the RStudio Project opens up again, run these three commands in the R Console:
Console
prodigenr::setup_with_git()usethis::use_blank_slate()usethis::use_r("functions", open =FALSE)
#> ✔ Setting active project to "/tmp/RtmpJNPNBu/LearnR3".
#> ℹ You'll need to restart RStudio to see the Git pane.
#> ✔ Setting RStudio preference 'save_workspace' to "never".
#> ✔ Setting RStudio preference 'load_workspace' to FALSE.
#> ✔ Creating '/home/runner/.config/rstudio/'.
#> ☐ Edit 'R/functions.R'.
#> ✔ Setting active project to "<no active project>".
Here we use the usethis package to help set things up. usethis is an extremely useful package for managing R Projects and we highly recommend checking it out more to see how you can use it more in your own work.
3.8 Quarto
We teach and use Quarto (which is a more powerful version of R Markdown) because it is one of the very first steps to being reproducible and because it is a very powerful tool to doing data analysis. Please do these two tasks:
Please read over the Quarto section of the introduction course. If you use Quarto already, you can skip this step.
Open up the LearnR3 project, either by clicking the LearnR3.Rproj file or by using the “File -> Open Project” menu. Run the function below in the Console when RStudio is in the LearnR3 project, which will create a new file called learning.qmd in the doc/ folder.
Console
r3::create_qmd_doc()
Throughout the course, we will use this document as a sandbox to test code out and then move the finished code to other files.
3.9 Download the course data
To best demonstrate the concepts in the course, we ideally should work on a real dataset to apply what we’re going to learn. So for this course, we’re going to use an openly licensed dataset on monitoring sleep and activity (MMASH) (1,2). To begin learning about being reproducible and applying modern approaches to data analysis, we’re going to write and save R code to download a dataset, prepare it a bit so it’s at least a little usable, and then save it to your computer. The goal at the end of the course is to create a pipeline to download the data, process and clean it, and save it in a form that makes it easier to analyze. Why don’t we get you to download an already cleaned and prepared dataset? Because in the real world, the data you get is rarely all cleaned up and ready for you, and this course is about learning more advanced tools to do the data wrangling. Look over these tasks and then switch over to the MMASH website:
Look through the Data Description to get familiar with the dataset and see what is contained inside of it. We’ll refer back to the Data Description throughout the course as well as in the exercises.
Look over the open license that allows you to re-use it, even for research purposes. Note: GDPR makes it stricter on how to share and use personal data, but it does not prohibit sharing it or making it public! GDPR and Open Data are not in conflict.
Note: Sometimes the PhysioNet website, where the MMASH data is described, is slow. If that’s the case, use this alternative link instead.
After looking over the MMASH website, you need to setup where to store the dataset to prepare it for later processing. While in your LearnR3 R Project, go to the Console pane in RStudio and type out:
Console
usethis::use_data_raw("mmash")
What this function does is create a new folder called data-raw/ and creates an R script called mmash.R in that folder. This is where we will store the raw, original MMASH data that we’ll get from the website. The R script should have opened up for you, otherwise, go into the data-raw/ folder and open up the new mmash.R script.
The first thing we want do is delete all the code in the script that is added there by default. Then we’ll create a new line at the top and type out:
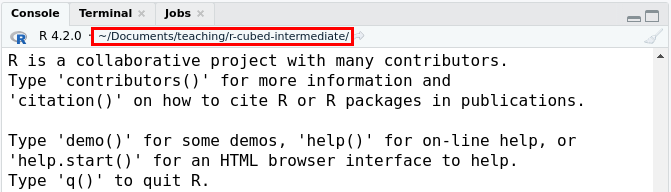
R works based on the current working directory, which you can see on the top of the RStudio Console pane, which you can see in the red box inside the image below. When in an RStudio R Project, the working directory is the folder where the .Rproj file is located. When you run scripts in R with source(), sometimes the working directory will be set to where the R script is located. So you can sometimes encounter problems with finding files. Instead, when you use here() R knows to start searching for files from the .Rproj location.
The folder location that R does it’s “work”, called the “working directory”, highlighted by the red box.
Let’s use an example. Below is the tree of the folders and files you have so far. If we open up RStudio with the LearnR3.Rproj file and run code in the data-raw/mmash.R, R runs the commands assuming everything starts in the LearnR3/ folder. But! If we run the code in the mmash.R script by other ways (e.g. not with RStudio, not in an R Project, or with source()), R runs everything assuming it starts in the data-raw/ folder. This can make things tricky. What here() does is tell R to first look for the .Rproj file and then start looking for the file we actually want. This might not make sense yet, but as we go through the course, you will see why this is important to consider.
Note
You don’t need to run the below code. But if you want to see the structure and content of a directory, you can use the dir_tree() function from the fs package, which means “filesystem”, by running the following code in the R Console:
Console
# To print the file list.fs::dir_tree("~/Desktop/LearnR3", recurse =1)
Note: Sometimes the PhysioNet website is slow. If that’s the case, use the r3::mmash_data_link instead of the link used above. In this case, it will look like mmash_link <- r3::mmash_data_link.
Then we’re going to write out the function download.file() to download and save the zip dataset. We’re going to save the zip file to data-raw/mmash-data.zip with the destfile argument. This code should be written in the data-raw/mmash.R file. Run these lines of code to download the dataset.
After downloading the zip file (it should be called mmash-data.zip in the data-raw/ folder), comment out this line, so that inside the data-raw/mmash.R script it looks like:
We do this because we don’t want to accidentally run this code again, since we already downloaded the file.
Because the original dataset is stored elsewhere on a website, we don’t need to save it to our Git history. Add the zip file to the Git ignore list by typing out and run this code in the Console. You only need to do this once.
Next, open up the zip file with your File Manager and look at what is inside. There should be the license file, another file to check if the download worked correctly (the SHA file, which you don’t need to worry about), and another zip file of the dataset. Because we are starting with the original raw mmash-data.zip, we should record exactly how we process the data set for use. This relates to the key principal of “keep your raw data raw”, as in don’t edit or touch your raw data, let R or another programming language process it. This lets you have a history of what was done to the raw data. During data collection and entry, programs like Excel or Google Sheets are incredibly powerful. But after collection is done, don’t make edits directly to the data unless absolutely necessary.
A quick comment about whether you should save your raw data in data-raw/. A general guideline is:
Do store it to data-raw/ if the data will only be used for the one project. Use the data-raw/ R script to be the record for how you processed your data for the final analysis work.
Don’t save it to data-raw/ if: 1) there is a central dataset that multiple people use for multiple projects; or 2) you have the data online. Instead, use the data-raw/ R script to be the record for which website or central location you extracted it from and how you later processed it.
Don’t save it to a project-specific data-raw/ folder if you will use the raw data for multiple projects. Instead, create a central location for the data for yourself so that you can point all other projects to it and use their individual data-raw/ R scripts as the record for how you processed the raw data.
We will eventually want to unzip the file, but before we begin, we want to include some code to always delete the unzipped output folder. We want to do this because sometimes unzipping can cause issues and because we want the script to always run everything cleanly from beginning to end whenever we source() it. In order to delete the folder, we’ll use the fs package to handle filesystem actions. Load the fs package with library() right below the other library() function at the top of the script:
data-raw/mmash.R
library(here)library(fs)
Next, we’ll use the dir_delete() to tell fs to always delete the data-raw/mmash/ output folder that we will create shortly. Put this below the dowload.file() code:
data-raw/mmash.R
# Remove leftover folder so unzipping is always cleandir_delete(here("data-raw/mmash"))
Now we can unzip the zip files by using the unzip() function and writing it in data-raw/mmash.R below the download.file() function. The main argument for unzip() is the zip file and the next important one is called exdir that tells unzip() which folder you want to extract the files to. The argument junkpaths is used here to tell unzip() to extract everything to the data-raw/ folder (no idea why it’s called “junkpaths”). This code should be written and executed in the data-raw/mmash.R script.
Notice the indentations and spacings of the code. Like writing any language, code should follow a style guide. An easy way of following a style is by selecting your code and using RStudio’s builtin style fixer with either Ctrl-Shift-A or Code -> Reformat Code menu item. Next, we’ll extract the new data-raw/MMASH.zip file using unzip() again. Because we want to keep the folder structure inside this zip file, we won’t use junkpaths. Write and execute this code in the data-raw/mmash.R script. We’ll also add a Sys.sleep(1) to pause the script for a second because sometimes the unzipping can be too fast and cause problems.
Almost done! There are several files left over that we don’t need, so you’ll need to write code in the script code that removes them. We’ll use the fs package to work with files. Before you change any files, look into the data-raw/ folder and confirm that the below listed files and folders are there.
Console
# NOTE: You don't need to run this code,# its here to show how we got the file list.fs::dir_tree("data-raw", recurse =1)
If your files and folders in the data-raw/ folder do not look like this, start over by deleting all the files except for the mmash.R and mmash-data.zip files. Then re-run the code from beginning to end.
To tidy up the files, first, use the file_delete() function from fs to delete all the files we originally extracted (LICENSE.txt, SHA256SUMS.txt, and MMASH.zip). Then use file_move() to rename the new folder data-raw/DataPaper/ to something more explicit like data-raw/mmash/. Add these lines of code to the data-raw/mmash.R script and run them:
Like before, if your files and folders inside data-raw/ don’t look like those listed above, start over again (making sure to delete all but the mmash.R and mmash-data.zip files).
Since we have an R script that downloads the data and processes it for us, we don’t need to have Git track it. So, in the Console, type out and run this command:
Console
usethis::use_git_ignore("data-raw/mmash/")
The data-raw/mmash.R script should look like this at this point:
data-raw/mmash.R
library(here)library(fs)# Downloadmmash_link <-"https://physionet.org/static/published-projects/mmash/multilevel-monitoring-of-activity-and-sleep-in-healthy-people-1.0.0.zip"# download.file(mmash_link, destfile = here("data-raw/mmash-data.zip"))# Remove leftover folder so unzipping is always cleandir_delete(here("data-raw/mmash"))# Unzipunzip(here("data-raw/mmash-data.zip"),exdir =here("data-raw"),junkpaths =TRUE)Sys.sleep(1)unzip(here("data-raw/MMASH.zip"),exdir =here("data-raw"))# Remove/tidy up left over filesfile_delete(here(c("data-raw/MMASH.zip","data-raw/SHA256SUMS.txt","data-raw/LICENSE.txt")))file_move(here("data-raw/DataPaper"), here("data-raw/mmash"))
Notice that in the file above, we have added comments to help segment sections in the code and explain what is happening in the script. In general, adding comments to your code helps not only when others read the script, but also you in the future, if/when you forget what was done or why it was done. It also creates sections in your code that makes it easier to get an overview of the code. However, there is a balance here. Too many comments can negatively impact readability, so as much as possible, write code in a way that explains what the code is doing, rather than rely on comments.
You now have the data ready for the course! At this point, please run this function in the Console:
The output should look something a bit like the above text. If it doesn’t, start over by deleting all but the mmash.R and mmash-data.zip files and running the code from the beginning again. If your output looks a bit like this, then copy and paste the output into the survey question at the end.
3.10 Basic course details
Most of the course description is found in the syllabus in Chapter 1. If you haven’t read it, please read it now. Read over what the course will cover, what we expect you to learn at the end of it, and what our basic assumptions are about who you are and what you know. The final pre-course task is a survey that asks some questions on if you’ve read and understood it.
One goal of the course is to teach about open science, and true to our mission, we practice what we preach. The course material is publicly accessible (all on this website) and openly licensed so you can use and re-use it for free! The material and table of contents on the side is listed in the order that we will cover in the course.
We have a Code of Conduct. If you haven’t read it, read it now. The survey at the end will ask about Conduct. We want to make sure this course is a supportive and safe environment for learning, so this Code of Conduct is important.
You’re almost done. Please fill out the pre-course survey to finish this assignment.